Reproducible Builds: Reproducible Builds in August 2023
Welcome to the August 2023 report from the Reproducible Builds project!
 In these reports we outline the most important things that we have been up to over the past month. As a quick recap, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries.
The motivation behind the reproducible builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. If you are interested in contributing to the project, please visit our Contribute page on our website.
In these reports we outline the most important things that we have been up to over the past month. As a quick recap, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries.
The motivation behind the reproducible builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised. If you are interested in contributing to the project, please visit our Contribute page on our website.
Rust serialisation library moving to precompiled binaries
Bleeping Computer reported that Serde, a popular Rust serialization framework, had decided to ship its serde_derive macro as a precompiled binary. As Ax Sharma writes:
The move has generated a fair amount of push back among developers who worry about its future legal and technical implications, along with a potential for supply chain attacks, should the maintainer account publishing these binaries be compromised.
After intensive discussions, use of the precompiled binary was phased out.
Reproducible builds, the first ten years
 On August 4th, Holger Levsen gave a talk at BornHack 2023 on the Danish island of Funen titled Reproducible Builds, the first ten years which promised to contain:
On August 4th, Holger Levsen gave a talk at BornHack 2023 on the Danish island of Funen titled Reproducible Builds, the first ten years which promised to contain:
[ ] an overview about reproducible builds, the past, the presence and the future. How it started with a small [meeting] at DebConf13 (and before), how it grew from being a Debian effort to something many projects work on together, until in 2021 it was mentioned in an executive order of the president of the United States. (HTML slides)
Holger repeated the talk later in the month at Chaos Communication Camp 2023 in Zehdenick, Germany:
A video of the talk is available online, as are the HTML slides.
Reproducible Builds Summit
 Just another reminder that our upcoming Reproducible Builds Summit is set to take place from October 31st November 2nd 2023 in Hamburg, Germany.
Our summits are a unique gathering that brings together attendees from diverse projects, united by a shared vision of advancing the Reproducible Builds effort. During this enriching event, participants will have the opportunity to engage in discussions, establish connections and exchange ideas to drive progress in this vital field.
If you re interested in joining us this year, please make sure to read the event page, the news item, or the invitation email that Mattia Rizzolo sent out, which have more details about the event and location.
We are also still looking for sponsors to support the event, so do reach out to the organizing team if you are able to help. (Also of note that PackagingCon 2023 is taking place in Berlin just before our summit, and their schedule has just been published.)
Just another reminder that our upcoming Reproducible Builds Summit is set to take place from October 31st November 2nd 2023 in Hamburg, Germany.
Our summits are a unique gathering that brings together attendees from diverse projects, united by a shared vision of advancing the Reproducible Builds effort. During this enriching event, participants will have the opportunity to engage in discussions, establish connections and exchange ideas to drive progress in this vital field.
If you re interested in joining us this year, please make sure to read the event page, the news item, or the invitation email that Mattia Rizzolo sent out, which have more details about the event and location.
We are also still looking for sponsors to support the event, so do reach out to the organizing team if you are able to help. (Also of note that PackagingCon 2023 is taking place in Berlin just before our summit, and their schedule has just been published.)
Vagrant Cascadian on the Sustain podcast
 Vagrant Cascadian was interviewed on the SustainOSS podcast on reproducible builds:
Vagrant Cascadian was interviewed on the SustainOSS podcast on reproducible builds:
Vagrant walks us through his role in the project where the aim is to ensure identical results in software builds across various machines and times, enhancing software security and creating a seamless developer experience. Discover how this mission, supported by the Software Freedom Conservancy and a broad community, is changing the face of Linux distros, Arch Linux, openSUSE, and F-Droid. They also explore the challenges of managing random elements in software, and Vagrant s vision to make reproducible builds a standard best practice that will ideally become automatic for users. Vagrant shares his work in progress and their commitment to the last mile problem.
The episode is available to listen (or download) from the Sustain podcast website. As it happens, the episode was recorded at FOSSY 2023, and the video of Vagrant s talk from this conference (Breaking the Chains of Trusting Trust is now available on Archive.org:
 It was also announced that Vagrant Cascadian will be presenting at the Open Source Firmware Conference in October on the topic of Reproducible Builds All The Way Down.
It was also announced that Vagrant Cascadian will be presenting at the Open Source Firmware Conference in October on the topic of Reproducible Builds All The Way Down.
On our mailing list
Carles Pina i Estany wrote to our mailing list during August with an interesting question concerning the practical steps to reproduce the hello-traditional package from Debian. The entire thread can be viewed from the archive page, as can Vagrant Cascadian s reply.
Website updates
Rahul Bajaj updated our website to add a series of environment variations related to reproducible builds [ ], Russ Cox added the Go programming language to our projects page [ ] and Vagrant Cascadian fixed a number of broken links and typos around the website [ ][ ][ ].
Software development
 In diffoscope development this month, versions
In diffoscope development this month, versions 247, 248 and 249 were uploaded to Debian unstable by Chris Lamb, who also added documentation for the new specialize_as method and expanding the documentation of the existing specialize as well [ ]. In addition, Fay Stegerman added specialize_as and used it to optimise .smali comparisons when decompiling Android .apk files [ ], Felix Yan and Mattia Rizzolo corrected some typos in code comments [ , ], Greg Chabala merged the RUN commands into single layer in the package s Dockerfile [ ] thus greatly reducing the final image size. Lastly, Roland Clobus updated tool descriptions to mark that the xb-tool has moved package within Debian [ ].
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian updated the packaging to be compatible with Tox version 4. This was originally filed as Debian bug #1042918 and Holger Levsen uploaded this to change to Debian unstable as version 0.7.26 [ ].
Distribution work
 In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new
In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new timestamp_in_documentation_using_sphinx_zzzeeksphinx_theme toolchain issue.
 In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
 Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
arimo (modification time in build results)apptainer (random Go build identifier)arrow (fails to build on single-CPU machines)camlp (parallelism-related issue)developer (Go ordering-related issue)elementary-xfce-icon-theme (font-related problem)gegl (parallelism issue)grommunio (filesystem ordering issue)grpc (drop nondetermistic log)guile-parted (parallelism-related issue)icinga (hostname-based issue)liquid-dsp (CPU-oriented problem)memcached (package fails to build far in the future)openmpi5/openpmix (date/copyright year issue)openmpi5 (date/copyright year issue)orthanc-ohif+orthanc-volview (ordering related issue plus timestamp in a Gzip)perl-Net-DNS (package fails to build far in the future)postgis (parallelism issue)python-scipy (uses an arbitrary build path)python-trustme (package fails to build far in the future)qtbase/qmake/goldendict-ng (timestamp-related issue)qtox (date-related issue)ring (filesytem ordering related issue)scipy (1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy (1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme (font-related issue)
-
Chris Lamb:
-
Rebecca N. Palmer:
Testing framework
 The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.json data file. [ ]
- Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgz for Debian unstable due to #1050784. [ ][ ]
- Correctly document that we are not variying
usrmerge. [ ][ ]
- Mark two
armhf nodes (wbq0 and jtx1a) as down; investigation is needed. [ ]
-
Misc:
-
System health checks:
In addition, Vagrant Cascadian updated the scripts to use a predictable build path that is consistent with the one used on buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Mastodon: @reproducible_builds@fosstodon.org
-
Twitter: @ReproBuilds
On August 4th, Holger Levsen gave a talk at BornHack 2023 on the Danish island of Funen titled Reproducible Builds, the first ten years which promised to contain:
[ ] an overview about reproducible builds, the past, the presence and the future. How it started with a small [meeting] at DebConf13 (and before), how it grew from being a Debian effort to something many projects work on together, until in 2021 it was mentioned in an executive order of the president of the United States. (HTML slides)Holger repeated the talk later in the month at Chaos Communication Camp 2023 in Zehdenick, Germany: A video of the talk is available online, as are the HTML slides.
Reproducible Builds Summit
Just another reminder that our upcoming Reproducible Builds Summit is set to take place from October 31st November 2nd 2023 in Hamburg, Germany.
Our summits are a unique gathering that brings together attendees from diverse projects, united by a shared vision of advancing the Reproducible Builds effort. During this enriching event, participants will have the opportunity to engage in discussions, establish connections and exchange ideas to drive progress in this vital field.
If you re interested in joining us this year, please make sure to read the event page, the news item, or the invitation email that Mattia Rizzolo sent out, which have more details about the event and location.
We are also still looking for sponsors to support the event, so do reach out to the organizing team if you are able to help. (Also of note that PackagingCon 2023 is taking place in Berlin just before our summit, and their schedule has just been published.)
Vagrant Cascadian on the Sustain podcast
Vagrant Cascadian was interviewed on the SustainOSS podcast on reproducible builds:
Vagrant walks us through his role in the project where the aim is to ensure identical results in software builds across various machines and times, enhancing software security and creating a seamless developer experience. Discover how this mission, supported by the Software Freedom Conservancy and a broad community, is changing the face of Linux distros, Arch Linux, openSUSE, and F-Droid. They also explore the challenges of managing random elements in software, and Vagrant s vision to make reproducible builds a standard best practice that will ideally become automatic for users. Vagrant shares his work in progress and their commitment to the last mile problem.
The episode is available to listen (or download) from the Sustain podcast website. As it happens, the episode was recorded at FOSSY 2023, and the video of Vagrant s talk from this conference (Breaking the Chains of Trusting Trust is now available on Archive.org:
It was also announced that Vagrant Cascadian will be presenting at the Open Source Firmware Conference in October on the topic of Reproducible Builds All The Way Down.
On our mailing list
Carles Pina i Estany wrote to our mailing list during August with an interesting question concerning the practical steps to reproduce the hello-traditional package from Debian. The entire thread can be viewed from the archive page, as can Vagrant Cascadian s reply.
Website updates
Rahul Bajaj updated our website to add a series of environment variations related to reproducible builds [ ], Russ Cox added the Go programming language to our projects page [ ] and Vagrant Cascadian fixed a number of broken links and typos around the website [ ][ ][ ].
Software development
In diffoscope development this month, versions 247, 248 and 249 were uploaded to Debian unstable by Chris Lamb, who also added documentation for the new specialize_as method and expanding the documentation of the existing specialize as well [ ]. In addition, Fay Stegerman added specialize_as and used it to optimise .smali comparisons when decompiling Android .apk files [ ], Felix Yan and Mattia Rizzolo corrected some typos in code comments [ , ], Greg Chabala merged the RUN commands into single layer in the package s Dockerfile [ ] thus greatly reducing the final image size. Lastly, Roland Clobus updated tool descriptions to mark that the xb-tool has moved package within Debian [ ].
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian updated the packaging to be compatible with Tox version 4. This was originally filed as Debian bug #1042918 and Holger Levsen uploaded this to change to Debian unstable as version 0.7.26 [ ].
Distribution work
In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new timestamp_in_documentation_using_sphinx_zzzeeksphinx_theme toolchain issue.
In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
arimo (modification time in build results)apptainer (random Go build identifier)arrow (fails to build on single-CPU machines)camlp (parallelism-related issue)developer (Go ordering-related issue)elementary-xfce-icon-theme (font-related problem)gegl (parallelism issue)grommunio (filesystem ordering issue)grpc (drop nondetermistic log)guile-parted (parallelism-related issue)icinga (hostname-based issue)liquid-dsp (CPU-oriented problem)memcached (package fails to build far in the future)openmpi5/openpmix (date/copyright year issue)openmpi5 (date/copyright year issue)orthanc-ohif+orthanc-volview (ordering related issue plus timestamp in a Gzip)perl-Net-DNS (package fails to build far in the future)postgis (parallelism issue)python-scipy (uses an arbitrary build path)python-trustme (package fails to build far in the future)qtbase/qmake/goldendict-ng (timestamp-related issue)qtox (date-related issue)ring (filesytem ordering related issue)scipy (1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy (1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme (font-related issue)
-
Chris Lamb:
-
Rebecca N. Palmer:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.json data file. [ ]
- Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgz for Debian unstable due to #1050784. [ ][ ]
- Correctly document that we are not variying
usrmerge. [ ][ ]
- Mark two
armhf nodes (wbq0 and jtx1a) as down; investigation is needed. [ ]
-
Misc:
-
System health checks:
In addition, Vagrant Cascadian updated the scripts to use a predictable build path that is consistent with the one used on buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Mastodon: @reproducible_builds@fosstodon.org
-
Twitter: @ReproBuilds
Vagrant Cascadian was interviewed on the SustainOSS podcast on reproducible builds:
Vagrant walks us through his role in the project where the aim is to ensure identical results in software builds across various machines and times, enhancing software security and creating a seamless developer experience. Discover how this mission, supported by the Software Freedom Conservancy and a broad community, is changing the face of Linux distros, Arch Linux, openSUSE, and F-Droid. They also explore the challenges of managing random elements in software, and Vagrant s vision to make reproducible builds a standard best practice that will ideally become automatic for users. Vagrant shares his work in progress and their commitment to the last mile problem.The episode is available to listen (or download) from the Sustain podcast website. As it happens, the episode was recorded at FOSSY 2023, and the video of Vagrant s talk from this conference (Breaking the Chains of Trusting Trust is now available on Archive.org:
It was also announced that Vagrant Cascadian will be presenting at the Open Source Firmware Conference in October on the topic of Reproducible Builds All The Way Down.
On our mailing list
Carles Pina i Estany wrote to our mailing list during August with an interesting question concerning the practical steps to reproduce the hello-traditional package from Debian. The entire thread can be viewed from the archive page, as can Vagrant Cascadian s reply.
Website updates
Rahul Bajaj updated our website to add a series of environment variations related to reproducible builds [ ], Russ Cox added the Go programming language to our projects page [ ] and Vagrant Cascadian fixed a number of broken links and typos around the website [ ][ ][ ].
Software development
In diffoscope development this month, versions 247, 248 and 249 were uploaded to Debian unstable by Chris Lamb, who also added documentation for the new specialize_as method and expanding the documentation of the existing specialize as well [ ]. In addition, Fay Stegerman added specialize_as and used it to optimise .smali comparisons when decompiling Android .apk files [ ], Felix Yan and Mattia Rizzolo corrected some typos in code comments [ , ], Greg Chabala merged the RUN commands into single layer in the package s Dockerfile [ ] thus greatly reducing the final image size. Lastly, Roland Clobus updated tool descriptions to mark that the xb-tool has moved package within Debian [ ].
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian updated the packaging to be compatible with Tox version 4. This was originally filed as Debian bug #1042918 and Holger Levsen uploaded this to change to Debian unstable as version 0.7.26 [ ].
Distribution work
In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new timestamp_in_documentation_using_sphinx_zzzeeksphinx_theme toolchain issue.
In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
arimo (modification time in build results)apptainer (random Go build identifier)arrow (fails to build on single-CPU machines)camlp (parallelism-related issue)developer (Go ordering-related issue)elementary-xfce-icon-theme (font-related problem)gegl (parallelism issue)grommunio (filesystem ordering issue)grpc (drop nondetermistic log)guile-parted (parallelism-related issue)icinga (hostname-based issue)liquid-dsp (CPU-oriented problem)memcached (package fails to build far in the future)openmpi5/openpmix (date/copyright year issue)openmpi5 (date/copyright year issue)orthanc-ohif+orthanc-volview (ordering related issue plus timestamp in a Gzip)perl-Net-DNS (package fails to build far in the future)postgis (parallelism issue)python-scipy (uses an arbitrary build path)python-trustme (package fails to build far in the future)qtbase/qmake/goldendict-ng (timestamp-related issue)qtox (date-related issue)ring (filesytem ordering related issue)scipy (1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy (1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme (font-related issue)
-
Chris Lamb:
-
Rebecca N. Palmer:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.json data file. [ ]
- Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgz for Debian unstable due to #1050784. [ ][ ]
- Correctly document that we are not variying
usrmerge. [ ][ ]
- Mark two
armhf nodes (wbq0 and jtx1a) as down; investigation is needed. [ ]
-
Misc:
-
System health checks:
In addition, Vagrant Cascadian updated the scripts to use a predictable build path that is consistent with the one used on buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Mastodon: @reproducible_builds@fosstodon.org
-
Twitter: @ReproBuilds
Software development
In diffoscope development this month, versions 247, 248 and 249 were uploaded to Debian unstable by Chris Lamb, who also added documentation for the new specialize_as method and expanding the documentation of the existing specialize as well [ ]. In addition, Fay Stegerman added specialize_as and used it to optimise .smali comparisons when decompiling Android .apk files [ ], Felix Yan and Mattia Rizzolo corrected some typos in code comments [ , ], Greg Chabala merged the RUN commands into single layer in the package s Dockerfile [ ] thus greatly reducing the final image size. Lastly, Roland Clobus updated tool descriptions to mark that the xb-tool has moved package within Debian [ ].
reprotest is our tool for building the same source code twice in different environments and then checking the binaries produced by each build for any differences. This month, Vagrant Cascadian updated the packaging to be compatible with Tox version 4. This was originally filed as Debian bug #1042918 and Holger Levsen uploaded this to change to Debian unstable as version 0.7.26 [ ].
Distribution work
In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new timestamp_in_documentation_using_sphinx_zzzeeksphinx_theme toolchain issue.
In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
arimo (modification time in build results)apptainer (random Go build identifier)arrow (fails to build on single-CPU machines)camlp (parallelism-related issue)developer (Go ordering-related issue)elementary-xfce-icon-theme (font-related problem)gegl (parallelism issue)grommunio (filesystem ordering issue)grpc (drop nondetermistic log)guile-parted (parallelism-related issue)icinga (hostname-based issue)liquid-dsp (CPU-oriented problem)memcached (package fails to build far in the future)openmpi5/openpmix (date/copyright year issue)openmpi5 (date/copyright year issue)orthanc-ohif+orthanc-volview (ordering related issue plus timestamp in a Gzip)perl-Net-DNS (package fails to build far in the future)postgis (parallelism issue)python-scipy (uses an arbitrary build path)python-trustme (package fails to build far in the future)qtbase/qmake/goldendict-ng (timestamp-related issue)qtox (date-related issue)ring (filesytem ordering related issue)scipy (1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy (1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme (font-related issue)
-
Chris Lamb:
-
Rebecca N. Palmer:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.json data file. [ ]
- Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgz for Debian unstable due to #1050784. [ ][ ]
- Correctly document that we are not variying
usrmerge. [ ][ ]
- Mark two
armhf nodes (wbq0 and jtx1a) as down; investigation is needed. [ ]
-
Misc:
-
System health checks:
In addition, Vagrant Cascadian updated the scripts to use a predictable build path that is consistent with the one used on buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Mastodon: @reproducible_builds@fosstodon.org
-
Twitter: @ReproBuilds
In Debian, 28 reviews of Debian packages were added, 14 were updated and 13 were removed this month adding to our knowledge about identified issues. A number of issue types were added, including Chris Lamb adding a new timestamp_in_documentation_using_sphinx_zzzeeksphinx_theme toolchain issue.
In August, F-Droid added 25 new reproducible apps and saw 2 existing apps switch to reproducible builds, making 191 apps in total that are published with Reproducible Builds and using the upstream developer s signature. [ ]
Bernhard M. Wiedemann published another monthly report about reproducibility within openSUSE.
Upstream patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where appropriate. This month, we wrote a large number of such patches, including:
-
Bernhard M. Wiedemann:
arimo (modification time in build results)apptainer (random Go build identifier)arrow (fails to build on single-CPU machines)camlp (parallelism-related issue)developer (Go ordering-related issue)elementary-xfce-icon-theme (font-related problem)gegl (parallelism issue)grommunio (filesystem ordering issue)grpc (drop nondetermistic log)guile-parted (parallelism-related issue)icinga (hostname-based issue)liquid-dsp (CPU-oriented problem)memcached (package fails to build far in the future)openmpi5/openpmix (date/copyright year issue)openmpi5 (date/copyright year issue)orthanc-ohif+orthanc-volview (ordering related issue plus timestamp in a Gzip)perl-Net-DNS (package fails to build far in the future)postgis (parallelism issue)python-scipy (uses an arbitrary build path)python-trustme (package fails to build far in the future)qtbase/qmake/goldendict-ng (timestamp-related issue)qtox (date-related issue)ring (filesytem ordering related issue)scipy (1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy (1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme (font-related issue)
-
Chris Lamb:
-
Rebecca N. Palmer:
Testing framework
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.json data file. [ ]
- Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgz for Debian unstable due to #1050784. [ ][ ]
- Correctly document that we are not variying
usrmerge. [ ][ ]
- Mark two
armhf nodes (wbq0 and jtx1a) as down; investigation is needed. [ ]
-
Misc:
-
System health checks:
In addition, Vagrant Cascadian updated the scripts to use a predictable build path that is consistent with the one used on buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-builds on irc.oftc.net.
-
Mailing list:
rb-general@lists.reproducible-builds.org
-
Mastodon: @reproducible_builds@fosstodon.org
-
Twitter: @ReproBuilds
arimo(modification time in build results)apptainer(random Go build identifier)arrow(fails to build on single-CPU machines)camlp(parallelism-related issue)developer(Go ordering-related issue)elementary-xfce-icon-theme(font-related problem)gegl(parallelism issue)grommunio(filesystem ordering issue)grpc(drop nondetermistic log)guile-parted(parallelism-related issue)icinga(hostname-based issue)liquid-dsp(CPU-oriented problem)memcached(package fails to build far in the future)openmpi5/openpmix(date/copyright year issue)openmpi5(date/copyright year issue)orthanc-ohif+orthanc-volview(ordering related issue plus timestamp in a Gzip)perl-Net-DNS(package fails to build far in the future)postgis(parallelism issue)python-scipy(uses an arbitrary build path)python-trustme(package fails to build far in the future)qtbase/qmake/goldendict-ng(timestamp-related issue)qtox(date-related issue)ring(filesytem ordering related issue)scipy(1 & 2) (drop arbtirary build path and filesytem-ordering issue)snimpy(1 & 3) (fails to build on single-CPU machines as well far in the future)tango-icon-theme(font-related issue)
The Reproducible Builds project operates a comprehensive testing framework (available at tests.reproducible-builds.org) in order to check packages and other artifacts for reproducibility. In August, a number of changes were made by Holger Levsen:
-
Debian-related changes:
- Disable Debian live image creation jobs until an OpenQA credential problem has been fixed. [ ]
- Run our maintenance scripts every 3 hours instead of every 2. [ ]
- Export data for unstable to the
reproducible-tracker.jsondata file. [ ] - Stop varying the build path, we want reproducible builds. [ ]
- Temporarily stop updating the
pbuilder.tgzfor Debian unstable due to #1050784. [ ][ ] - Correctly document that we are not variying
usrmerge. [ ][ ] - Mark two
armhfnodes (wbq0andjtx1a) as down; investigation is needed. [ ]
- Misc:
- System health checks:
buildd.debian.org. [ ][ ]
If you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:
-
IRC:
#reproducible-buildsonirc.oftc.net. -
Mailing list:
rb-general@lists.reproducible-builds.org - Mastodon: @reproducible_builds@fosstodon.org
- Twitter: @ReproBuilds
 Release 1.1.57-4 of the
Release 1.1.57-4 of the  CRAN processed the package fully automatically as it has no issues, and
nothing popped up in reverse-dependency checking.
The set of changes for the last two RcppArmadillo releases
follows.
CRAN processed the package fully automatically as it has no issues, and
nothing popped up in reverse-dependency checking.
The set of changes for the last two RcppArmadillo releases
follows.
 Apparently it s nearly four years since I last posted to my blog. Which is, to a degree, the point here. My time, and priorities, have changed over the years. And this lead me to the decision that my available time and priorities in 2023 aren t compatible with being a Debian or Ubuntu developer, and realistically, haven t been for years. As of earlier this month, I quit as a Debian Developer and Ubuntu MOTU.
I think a lot of my blogging energy got absorbed by social media over the last decade, but with the collapse of Twitter and Reddit due to mismanagement, I m trying to allocate more time for blog-based things instead. I may write up some of the things I ve achieved at work (.NET 8 is now snapped for release Soon
Apparently it s nearly four years since I last posted to my blog. Which is, to a degree, the point here. My time, and priorities, have changed over the years. And this lead me to the decision that my available time and priorities in 2023 aren t compatible with being a Debian or Ubuntu developer, and realistically, haven t been for years. As of earlier this month, I quit as a Debian Developer and Ubuntu MOTU.
I think a lot of my blogging energy got absorbed by social media over the last decade, but with the collapse of Twitter and Reddit due to mismanagement, I m trying to allocate more time for blog-based things instead. I may write up some of the things I ve achieved at work (.NET 8 is now snapped for release Soon ). I might even blog about work-adjacent controversial topics, like my changed feelings about the entire concept of distribution packages. But there s time for that later. Maybe.
I ll keep tagging vaguely FOSS related topics with the Debian and Ubuntu tags, which cause them to be aggregated in the Planet Debian/Ubuntu feeds (RSS, remember that from the before times?!) until an admin on those sites gets annoyed at the off-topic posting of an emeritus dev and deletes them.
But that s where we are. Rather than ignore my distro obligations, I ve admitted that I just don t have the energy any more. Let someone less perpetually exhausted than me take over. And if they don t, maybe that s OK too.
). I might even blog about work-adjacent controversial topics, like my changed feelings about the entire concept of distribution packages. But there s time for that later. Maybe.
I ll keep tagging vaguely FOSS related topics with the Debian and Ubuntu tags, which cause them to be aggregated in the Planet Debian/Ubuntu feeds (RSS, remember that from the before times?!) until an admin on those sites gets annoyed at the off-topic posting of an emeritus dev and deletes them.
But that s where we are. Rather than ignore my distro obligations, I ve admitted that I just don t have the energy any more. Let someone less perpetually exhausted than me take over. And if they don t, maybe that s OK too.
 Now that
Now that  Turns out maybe not so much (yet ?). As the
Turns out maybe not so much (yet ?). As the 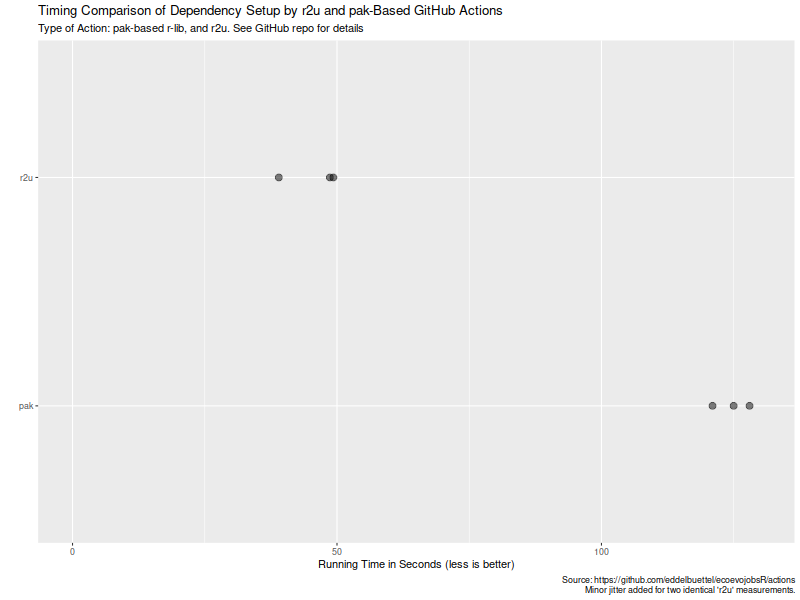 Now, this is of course entirely possibly that not all possible venues
for speedups were exploited in how the action setup was setup. If so,
please file an issue at the
Now, this is of course entirely possibly that not all possible venues
for speedups were exploited in how the action setup was setup. If so,
please file an issue at the  I've been maintaining a number of Perl software packages recently.
There's
I've been maintaining a number of Perl software packages recently.
There's  The first time you do this, it will open up a new browser tab where
your Codespace is being instantiated. This first-time instantiation
will take a few minutes (feel free to click View logs to see how
things are progressing) so please be patient. Once built, your Codespace
will deploy almost immediately when you use it again in the future.
The first time you do this, it will open up a new browser tab where
your Codespace is being instantiated. This first-time instantiation
will take a few minutes (feel free to click View logs to see how
things are progressing) so please be patient. Once built, your Codespace
will deploy almost immediately when you use it again in the future.
 After the VS Code editor opens up in your browser, feel free to open
up the
After the VS Code editor opens up in your browser, feel free to open
up the  (Both example screenshots reflect the initial
(Both example screenshots reflect the initial 


 This post describes how to deploy
This post describes how to deploy 
 The phrase "Root of Trust" turns up at various points in discussions about verified boot and measured boot, and to a first approximation nobody is able to give you a coherent explanation of what it means[1]. The Trusted Computing Group has a fairly wordy
The phrase "Root of Trust" turns up at various points in discussions about verified boot and measured boot, and to a first approximation nobody is able to give you a coherent explanation of what it means[1]. The Trusted Computing Group has a fairly wordy